The Java-RDF Mapper module
This Apache-Jena based module enables mapping Java classes to RDF data managed in a SPARQL endpoint and vice versa.
Features
- Growing support for JPA criteria queries: Write queries against Java domain models and don’t bother with the RDF specifics.
- A set of annotations for conveniently mapping classes a developer has control over. By default, the annotation processor evaluates many arguments as Spring Expression Language (SpEL) expressions and subsequently expands namespace declarations of IRIs where appropriate.
- Sping-based component scanning for populating the model of the mappings
- Extension points for creating custom mappers for classes and properties.
- View-based approach: Java classes are seen as ‘views’ over RDF resources, hence, multiple views over an RDF resource may exist. Each view is associated with a set of triples - removals affect all views.
A simple example
@RdfType("dbo:Company")
@DefaultIri("dbr:#{label}")
public static class Company {
//@Lang("en")
@Iri("rdfs:label")
private String label;
@IriNs("dbo")
@Datatype("xsd:gYear")
private int foundingYear;
@IriNs("dbo")
private int numberOfLocations;
// getters and setters omitted for brevity
}
This is an excerpt from the MainExampleMapperDBpedia.java class:
public class MainMapperDBpedia {
public static void main(String[] args) throws Exception {
/*
* Boiler plate code for setup
*/
SparqlEntityManagerFactory emFactory = new SparqlEntityManagerFactory();
emFactory.getPrefixMapping()
.setNsPrefix("schema", "http://schema.org/")
.setNsPrefix("dbo", "http://dbpedia.org/ontology/")
.setNsPrefix("dbr", "http://dbpedia.org/resource/")
.setNsPrefix("nss", "http://example.org/nss/");
emFactory.addScanPackageName(MainMapperDBpedia.class.getPackage().getName());
emFactory.setSparqlService(FluentSparqlService
.http("http://dbpedia.org/sparql", "http://dbpedia.org")
.config().configQuery()
.withParser(SparqlQueryParserImpl.create())
.withPagination(50000)
.end().end().create());
EntityManager em = emFactory.getObject();
/*
* Query 1: Companies founded after 1955 with more than 36000 locations
*/
List<Company> matches = JpaUtils.getResultList(em, Company.class, (cb, cq) -> {
Root<Company> r = cq.from(Company.class);
cq.select(r)
.where(cb.greaterThanOrEqualTo(r.get("foundingYear"), 1955))
.where(cb.greaterThanOrEqualTo(r.get("numberOfLocations"), 36000))
;
});
for(Company c : matches) {
System.out.println("Matched: " + c);
}
/*
* Query 2: Avg number of locations of all companies
*/
Double avg = JpaUtils.getSingleResult(em, Double.class, (cb, cq) -> {
Root<Company> r2 = cq.from(Company.class);
cq.select(cb.avg(r2.get("numberOfLocations")));
}).doubleValue();
System.out.println("Average number of locations: " + avg);
}
}
Usage
// Create an in-memory SPARQL service backed by a Jena model
SparqlService sparqlService = FluentSparqlService.forModel().create();
Prologue prologue = new Prologue();
// Add prefix declarations to prologue
RdfTypeFactory typeFactory = RdfTypeFactoryImpl.createDefault(prologue);
RdfMapperEngine engine = new RdfMapperEngineImpl(sparqlService);
Person entity = new Person(1);
engine.merge(entity);
// Write out the triples
Model model = sparqlService.getQueryExecutionFactory().createQueryExecution("CONSTRUCT WHERE { ?s ?p ?o }").execConstruct();
model.write(System.out, "TTL");
// Look up a class with a certain ID
Person p = engine.find(Person.class, "ex:0");
System.out.println("Found: " + p);
How does the system work in a nutshell?
There are two aspects to the system:
- The mapping between an RDF graph rooted in a given resource to the Java object graph and vice versa. Note that a set of resources can be described by a SPARQL query with a designated variable.
- The rewriting of criteria queries to SPARQL concepts
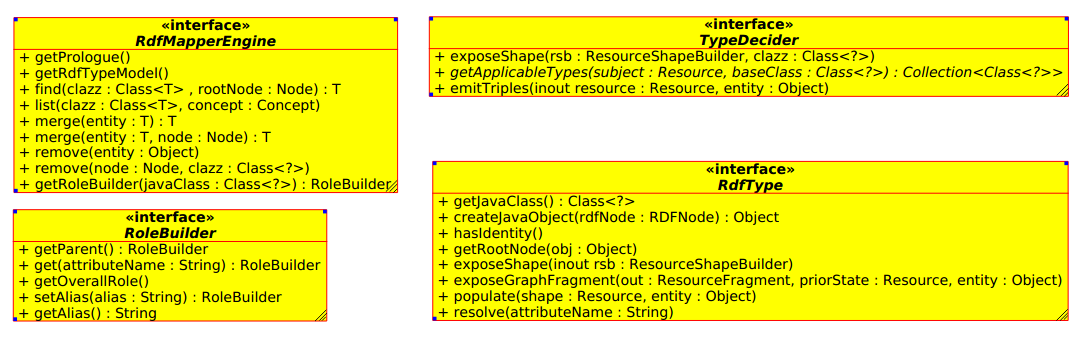
Annotations
| Annotation | Target | Value | Description |
|---|---|---|---|
| DefaultIri | Class | String | Assigns a default rule to generate IRIs for instances of the class. It is valid for RDF resources corresponding to this class (which may e.g. be stored in a triple store) to have IRIs that do not follow this pattern. |
| RdfType | Class | - | This annotation work in two ways: On the one hand, each resource corresponding to this class is associated with the provided type. On the other hand, all resources of that type define the set of class instances which can be created from the RDF data. |
| Iri | Property | String | Assigns an IRI to an attribute |
| IriNs | Property | String | Shorthand to assign an IRI to an attribute: The attribute name is appended to the given namespace |
| MultiValued | Property (of type Collection) | - | Controls the RDF mapping strategy of Java collections. MultiValued creates for each item of the collection a triple with the property’s corresponding IRI |
###
Constraints
Filtering by (orderde) SPARQL concepts.
It is possible to retrict the set of resources for which to obtain their corresponding Java instances by a SPARQL concept:
Concept concept = Concept.parse("?s ex:id ?id . FILTER(?id < 10)", "s", prologue);
List<Person> people = engine.list(Person.class, concept);
Note, that there also exists ordered SPARQL concepts, which extend SPARQL concepts with sort conditions.
Filtering using criteria
The approach of filtering by SPARQL concepts has the disadvantage, that these queries are tied to the target RDF model rather than the Java domain model and thus break abstraction. The alternative is to use the JPA criteria API, which will internally compile the queries to ordered concepts.
The mapper’s implementation of the criteria API in a first step populates a criteria query modelfrom the method invocations. This model includes expressions. In a subsequent step, these expressions are passed to the ExpressionCompiler in order to obtain a SPARQL expression.
Registering Java-RDF mappings for primitive types
The mapper uses Jena’s TypeMapper to convert between Java objects and RDF terms. This is not only used for primitive datatypes, such as int, String, … and (the boxed versions, such as Integer) but also classes such as Calendar.
TypeMapper tm = TypeMapper.getInstance();
tm.register(new CustomRDFDatatype());
By default, the typeMapper is consulted first. If it does not return an RdfType for a given class, the type is considered to be complex, and another handler is invoked, as described in the next section.
Registering handlers for complex types
The mapper consults a function for determining a class’s corresponding description in terms of an EntityOps instance. A custom function can be provided for handling custom types.
Function<Class<?>, EntityOps> classToOps = (clazz) -> EntityModel.createDefaultModel(clazz);
RdfTypeFactory typeFactory = RdfTypeFactoryImpl.createDefault(null, classToOps);
Overriding constructors, properties and annotations of entity classes
There exist various tooling for obtaining a model about a bean’s features. Java features the BeanInfo class and the spring framework features the BeanWrapper. However, in some cases we need to overwrite properties of a bean, such as providing a custom ‘default constructor’ for a class which does not define one.
For this reason, we introduce the EntityModel and PropertyModel classes, which are sub-classes of EntityOps and PropertyOps. Whereas EntityOps provides a newInstance() method, EntityModel allows setting a custom supplier to which the request is delegated to.
EntityModel entityModel = EntityModel.createDefaultModel(Person.class);
// Note: Person does not have a default constructor
entityModel.setNewInstance(() -> new Person(1, "John Doe"));
Mocking
TODO: We could extend the createDefaultModel function to automatically mock constructor arguments - e.g. Mockito