Unofficial extensions for jena - refactoring of https://github.com/SmartDataAnalytics/jena-sparql-api
Maven Dependencies
We recommend to import the jenax bom file in order to ensure consistent versions among the dependencies:
<dependency>
<groupId>org.aksw.jenax</groupId>
<artifactId>jenax-bom</artifactId>
<version>${jenax.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
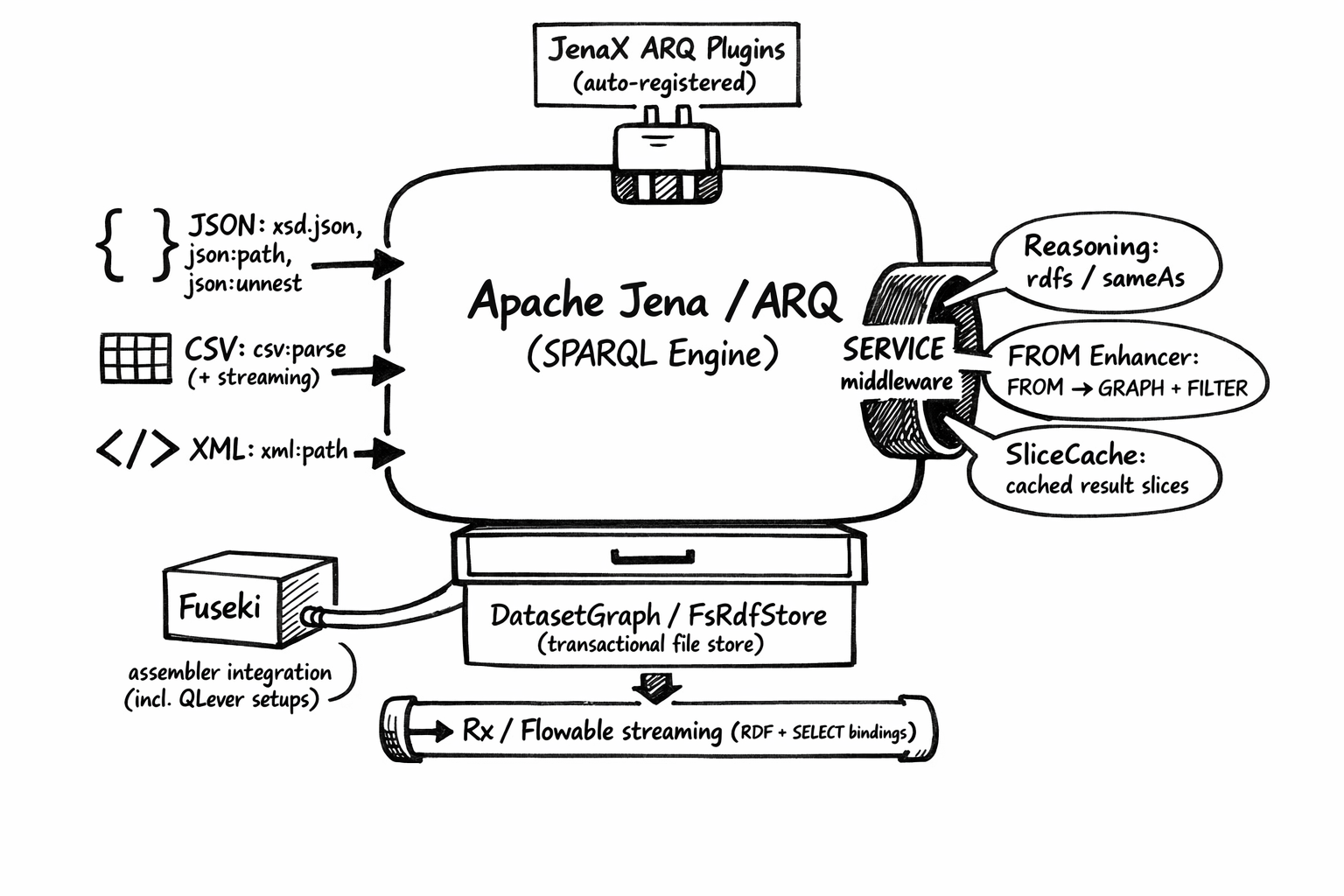
Highlights
Some components that deserve particular recognition:
FunctionBinder: Annotate Java functions and let the function binder do the work to enable their use in SPARQL.Reprogen(Resource Proxy Generator): Tired of writing code to brigde the Java object world with the RDF graph world? Let reprogen generate those bindings from annotated interfaces. Supports generation of mutablejava.util.{Set, List, Map}views that read/write through to a Jena Model. Do you need an approach to generate IRIs for your classes in a controlled and deterministic way from only a subset of the RDF graph that backs your object graph? Then you may want to give Reprogen’s annotation-based skolemizer a try.SliceCache: Low-latency caching of slices of SPARQL result sets. Clients can read slices of data concurrently while they are being retrieved. A configurable amount of pages is kept in an LRU (least-recently-used) memory cache and after a configurable delay they are synced to disk.BinarySearcher: A hadoop-based implementation for performing binary search on seekable streams. Allows for looking up information by subject in (compressed) ntriples files. The DBpedia Databus is a data catalog system that forsaw this use case and already provides the appropriate metadata.
Qlever Integration
- Install our jena fork. Our JenaX code relies on fixes and improvements of the
jena-serviceenhancermodule. These improvements need yet to be played back to the official Jena.
git clone https://github.com/Aklakan/jena.git jena-se
cd jena-se
git switch se-fixes-2023-11-29
mvn -Dmaven.test.skip clean install
- Build the JenaX plugins bundle, which includes the Qlever assembler. Note that
FUSEKI_EXTRA_JARS_FOLDERis the folder for extra jars of your Fuseki setup.
# Run these commands from <jenax-project-root> to build the plugins bundle:
cd jenax-bom
mvn -T1C -Dmaven.test.skip -Pext -pl :jenax-arq-plugins-bundle -am clean package
cd ..
cp ./jenax-arq-parent/jenax-arq-plugins-parent/jenax-arq-plugins-bundle/target/jenax-arq-plugins-bundle-5.5.0-1-SNAPSHOT.jar \
FUSEKI_EXTRA_JARS_FOLDER
- Create an assembler configuration such as
<fuseki-root>/run/configuration/qlever_ds.ttl:
PREFIX fuseki: <http://jena.apache.org/fuseki#>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX ja: <http://jena.hpl.hp.com/2005/11/Assembler#>
PREFIX qlever: <http://jena.apache.org/qlever#>
<#service> rdf:type fuseki:Service ;
fuseki:name "qlever" ;
fuseki:endpoint [
fuseki:operation fuseki:query ;
] ;
fuseki:dataset <#baseDS>
.
<#baseDS> rdf:type qlever:Dataset ;
qlever:location "/run/databases/qlever/mydb/" ;
qlever:indexName "myindex" ;
qlever:accessToken "abcde" ;
qlever:memoryMaxSize "4G" ;
qlever:defaultQueryTimeout "600s" ;
.
Docker-outside-of-Docker (DooD) Setup.
If Fuseki runs in a docker container then it can start qlever as a secondary container based on the assembler config. However, this requires additional configuration which may differ between environments. The following describes a typical setup on Ubuntu 24.04.
docker-compose.yml:
In this setup:
- Fuseki under the current user’s UID and GID (->
APP_UID,APP_GID) - Mounts the docker socket into the container (
/var/run/docker.sock) - Adds the container’s user to the docker group (->
group_addofDOCKER_GID) - Caveat: A firewall may prevent the Fuseki docker container from communicating with the
ryukcontainer from the TestContainers framework.
name: semantic-stack
services:
fuseki:
image: aksw/fuseki-geoplus:5.5.0-1
init: true
user: "${APP_UID}:${APP_GID}"
environment:
- JAVA_OPTIONS=-Xmx8G -XX:ReplayDataFile=/run/log/fuseki_replay_pid%p.log -XX:ErrorFile=/run/log/fuseki_hs_err_pid%p.log -Dderby.stream.error.file=/run/log/fuseki_derby.log
- FUSEKI_BASE=/run
group_add:
- "${DOCKER_GID}"
volumes:
- ./run:/run
- /var/run/docker.sock:/var/run/docker.sock
ports:
- 3030:3030
- 5005:5005
restart: unless-stopped
networks:
- semantic-stack-net
networks:
semantic-stack-net:
Invocation (feel free to use a .env file for the env variables):
APP_UID=`id -u` \
APP_GID=`id -g` \
DOCKER_GID=`getent group docker | cut -d: -f3` \
docker compose -f docker-compose.yml up